Machine-learning, Intelligence Artificielle (IA), sites contaminés et industries : quelles perspectives pour le machine-learning et l’IA dans le domaine des sites et sols pollués ?
02 juin 2020Paru dans le N°432
à la page 59 ( mots)
Rédigé par : Antoine EUDE de ENVISOL
En France, le seuil (ou l’objectif) de dépollution est défini individuellement pour chaque site en fonction des contraintes sanitaires et des caractéristiques de la contamination (localisation spatiale, masse totale de polluant, etc.). Ce seuil est flexible, il inclut des aspects économiques de coûts de traitement, les contraintes terrains et va de pair avec la notion de pollution résiduelle qui correspond à la pollution laissée sur site.
La possibilité de ‘personnaliser’ le seuil de décontamination d’un site est précieuse car elle offre de l’élasticité et permet de s’ajuster de façon raisonnée au cas par cas. Mais elle apporte également une contrainte : celle de caractériser la contamination le plus précisément possible !
Des méthodologies traditionnelles
La caractérisation environnementale d’un site se fait classiquement comme suit :
Une phase de recherche sur l’historique des activités du site et la localisation des zones à risque de contamination ;
Une phase de terrain : réalisation de sondages à l’aide de foreuses et prélèvement des échantillons de sols ;
L’analyse des échantillons de sols par des laboratoires (certifiés) ;
L’interprétation de ces résultats par un consultant.
Les opérations de terrain et l’analyse des échantillons sont les étapes les plus coûteuses de la caractérisation. Il s’agit par conséquence de postes sensibles dans la construction des programmes de caractérisation, et les contraintes de budgets limitent souvent la quantité de sondages et d’analyses.
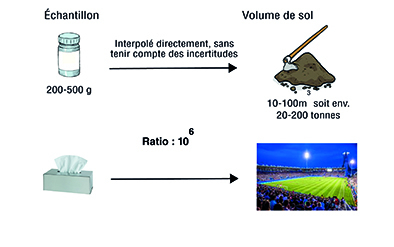
À cette première contrainte financière, s’ajoute une autre notion : celle de la représentativité. Un échantillon envoyé en laboratoire pèse entre 200 et 500g. Le résultat brut de l’analyse est ensuite appliqué - sans tenir compte du changement d’échelle - à des masses de l’ordre de la dizaine de tonne de sol. Le ratio entre ces deux grandeurs est de 106. A titre de comparaison cela revient à considérer équivalente la surface d’un mouchoir à celle d’un terrain de foot. Si ce ratio donne déjà le vertige, dites-vous que l’analyse de notre échantillon ne se fait que sur 1/10 du pot, que l’hétérogénéité des sols n’a pas été intégrée (nous sommes entre géologues après tout !), ni les erreurs d’échantillonnages et la liste continue… Bref la donnée laboratoire est relative mais il est possible de travailler avec elle dans de bonnes conditions.
Vous l’avez deviné, les observations réalisées amènent la notion d’incertitudes sur la mesure en laboratoire – et la nécessité d’intégrer ces incertitudes à l’échelle d’un site contaminé. Il existe des techniques qui permettent de quantifier et voire même de réduire ces incertitudes liées à cette représentativité de l’échantillon. Citons particulièrement :
Les mesures sur site. Il s’agit de tous les types de mesures qu’il est possible de réaliser en temps réel sur le site : analyses XRF, REMSCAN, PID, Kit colorimétrique, etc. Ces mesures complètent les analyses de laboratoire. Elles sont moins précises mais aussi significativement moins chères et plus rapides ce qui permet une multiplication aisée du nombre de données en une journée de terrain. Elles permettent donc de caractériser beaucoup plus finement les sites contaminés, réduisant ainsi les incertitudes.
Ces mesures sont toutefois considérées inférieures aux analyses de laboratoire qui ont une portée légale. Les autorités régulatrices dans le domaine des sites contaminés (DREAL1, ministères, etc.) vont en effet s’appuyer sur ces dernières en priorité pour valider les conclusions des caractérisations environnementales.
1 Directions Régionales de l’Environnement, de l’Aménagement et du Logement
Figure 1: Traitement ‘standard’ des données environnementales.
La géostatistique permet de quantifier l’incertitude. En effet, spatialiser l’information et modéliser en 3 dimensions la contamination permet de relativiser les données laboratoires. La géostatistique fait primer la cohérence du volume impacté dans son ensemble sur les valeurs brutes des sondages prises individuellement.
Cet outil est puissant et encore sous utilisé dans l’industrie mais nécessite une certaine quantité de sondages et d’analyses pour être pleinement efficace (en règle du pouce, une trentaine d’analyses à minima). La géostatistique ne résout pas à elle seule la problématique du nombre de sondages qui est souvent trop faible pour caractériser précisément les sites contaminés.
Nous avons enfin touché ici la problématique que l’intelligence artificielle ou le machine-learning peuvent résoudre : établir une relation entre les mesures sur site et les données laboratoires.
Le machine-learning pour prédire des résultats de laboratoire à partir des mesures in-situ
Traiter les mesures in-situ ces mesures complémentaires aux analyses de laboratoire, moins précises mais bien plus rapides et bon marché – devient un enjeu important pour s’adapter aux innovations dans le domaine des sites et sols contaminés. Deux solutions sont envisageables :
Le traitement géostatistique de ces mesures en co-variables des analyses de laboratoire classiques (cokrigeage notamment). L’intérêt des mesures in-situ est alors de renforcer les estimations de volumes en maillant plus finement le site à l’étude.
La valeur laboratoire reste la référence, les mesures de terrain viennent seulement appuyer les estimations.
Le traitement de ces mesures à l’aide d’approches machine-learning afin de prédire l’analyse de laboratoire. Cette approche est complètement différente car il s’agit de transformer les mesures in-situ en un équivalent de laboratoire - leur donnant une portée légale.
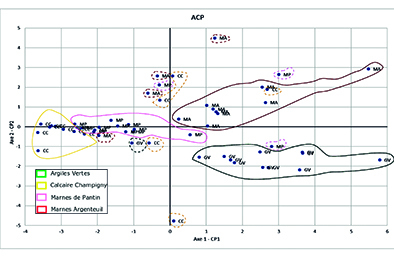
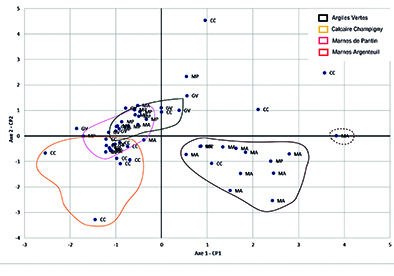
Figure 2: ACP sur les mesures de laboratoire et les mesures in-situ. Les deux composantes principales sont projetées dans le plan. Interprétation à « main levée » des signatures géochimiques par lithologie.
Dans ce cadre, les mesures in-situ deviennent la référence – et peuvent aller jusqu’à remplacer les analyses de laboratoire.
Pourquoi parler de machine-learning qui est souvent attaché aux notions de Big Data, et non d’une approche statistique ? Surfons-nous sur du Buzz Word ?
Oui et non ! C’est sûr qu’une partie de ce qu’on appelait statistiques hier est maintenant intégré dans la famille du machine-learning mais ce sont bien des propriétés propres à ce champ d’expertise que nous cherchons.
Les modèles de type machine-learning gèrent efficacement des jeux de données au comportement erratique– courants dans le domaine des géosciences (l’hétérogénéité est un euphémisme dans notre domaine). Nous l’avons dit, les mesures in-situ sont moins précises que les analyses de laboratoire. La figure ci-dessous en est un exemple : les analyses de laboratoire discriminent efficacement les lithologies du Grand-Paris par leurs signatures géochimiques. A l’inverse sur les mêmes échantillons les mesures de terrain ne sont pas suffisamment précises pour distinguer efficacement les lithologies.
Des algorithmes complexes permettent de travailler sur ces données : citons par exemple la famille des Forêts Aléatoires (Random-Forest) qui regroupe des algorithmes régulièrement utilisés dans le cadre des jeux de données géoscientifiques pour leur flexibilité.
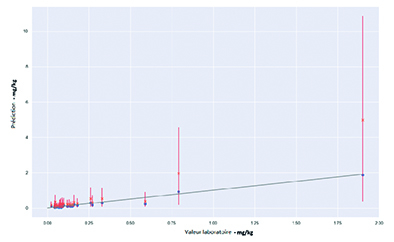
Les modèles de type machine-learning supportent la multiplication des prédicteurs, priorisent et permettent d’expérimenter sans trop de contraintes… Il existe une multitude de façon de traiter des sources d’informations totalement différentes : des photos aux spectres d’émissions en passant par les observations de terrain. Les algorithmes peuvent s’alimenter de toutes ces sources pour répondre à une finalité dans un cadre défini ou non (on parle d’algorithmes supervisés ou non supervisés). Si d’une manière générale, un grand nombre de données est nécessaire pour des modèles stables, il existe des manières de travailler avec des jeux de données plus réduits. Dans ce dernier cas, la clé est de modéliser les incertitudes sur la prédiction – notamment en produisant comme résultat une distribution de valeur plutôt qu’une estimation « fixe ». En illustration ci-dessous, la corrélation entre les prédictions d’un algorithme de type GLM et les analyses de laboratoire. L’objectif était de prédire la concentration en antimoine des échantillons à partir des mesures in-situ réalisées par un appareil XRF de terrain. Les prédictions - qui suivent une loi de distribution Gamma (point bleu : médiane de la distribution, croix rouge : moyenne de la distribution) - permettent de rendre compte de la marge d’erreur que présente le modèle. Un tel modèle est inopérant à réaliser des prédictions fiables pour les fortes concentrations (disons > 1 mg/kg). Pour les échantillons qui ont de telles concentrations en antimoine, la gamme de réponse de l’algorithme varie de 0.5 à 11 mg/kg !
Figure 3: Diagnostic sur la capacité d’un modèle de ML à prédire des valeurs de laboratoire.
Une des méthodes utilisées pour améliorer la prédiction a été d’inclure dans les prédicteurs un traitement sur les photos des échantillons. Cette étape à elle seule permet de diviser par 3 l’étendue des distributions, améliorant la précision des prédictions.
Par cet exemple, nous touchons là un aspect spécifique au domaine des sites et sols contaminés : nos enjeux portent sur les valeurs extrêmes, les outliers, parce que ce sont elles qui indiquent la présence de contamination. Nous nous intéressons donc davantage à modéliser précisément les quelques occurrences de fortes valeurs (dans l’exemple plus haut, les valeurs supérieures à 1 qui indique une « contamination » en antimoine) que la distribution en elle-même. Là encore la grande famille du machine-learning s’impose par rapport aux méthodologies purement statistiques, au travers des algorithmes de détection d’outliers par exemple.
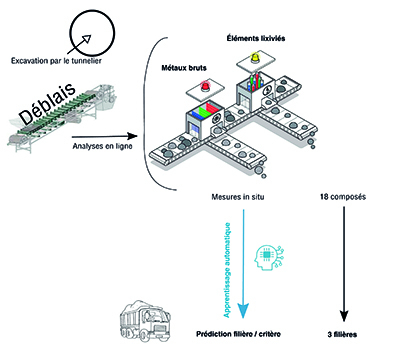
Exemple d’un cas d’industrialisation : travaux sur les tunneliers du Grand-Paris
Sur ce projet, nous avons pu développer des algorithmes de machine-learning qui permettent de déterminer les filières d’évacuation des sols de manière instantanée à l’aide de mesures in-situ. Le taux de réussite par rapport aux analyses de laboratoire est de l’ordre de 95%.
Figure 4: Utilisation du machine-learning dans la gestion des déblais d’un tunnelier.
Le gain financier est conséquent car la filière d’évacuation des déblais peut être connue avant même que les sols soient sortis du tunnelier. En comparaison, la méthode traditionnelle consiste à stocker les déblais, réaliser des analyses de laboratoire (délais de plusieurs jours) puis envoyer les déblais vers les centres adéquats en fonction des résultats des analyses.
La principale difficulté technique dans le cadre de ce projet était la suivante : les algorithmes devaient être entraînés sur la variabilité des valeurs qu’ils ont à prévoir. De manière plus imagée, imaginez que vous ayez à deviner ce que représente une image avec seulement 10% de ces pixels visibles. Si ces 10% de pixels sont répartis un peu partout sur l’image, il est plus facile de prédire ce qui est représenté que s’ils sont tous inclus dans le coin en bas à gauche.
Un tunnelier avançant de manière linéaire, il est difficile de prévoir les poches d’hétérogénéité (courantes en géologie) avant de tomber dessus. L’algorithme est alors capable de gérer cette hétérogénéité proportionnellement à la robustesse (et quelque part la quantité de données) du jeu d’entraînement. Une mise à jour régulière des modèles permet d’augmenter la robustesse de ces derniers.
Finalement, effet de mode ou changement de fond ?
Les technologies de l’IA et du machine-learning apportent des outils puissants pour traiter les données environnementales et permettent de valoriser des sources d’informations trop souvent mises de côté. En France, avec une réglementation permettant de traiter au cas par cas les sites contaminés, nous avons beaucoup à gagner à utiliser et à développer nos expertises dans le traitement de données. La géostatistique et le machine-learning sont des leviers pour améliorer la caractérisation des sites contaminés, diminuer les coûts associés et avoir une gestion environnementale plus efficace de nos territoires.
Le machine-learning répond à un besoin et, je crois, à un changement de fond plutôt qu’à un effet de mode. Les mentalités sont déjà en train d’évoluer et on prend progressivement conscience que les données sont une ressource que l’on doit mettre à profit.
Cet article est réservé aux abonnés, pour lire l'article en entier abonnez vous ou achetez le